Spring cloud
总阅读 次
Spring Cloud
近期把springcloud整体又体验了一把,亲手搭建demo,此处记录一些过程中遇到的细节点。简单描述,便于自己今后理解,具体搭建细节,见下面的学习资源。
学习的资源来自:史上最简单的 SpringCloud 教程,感谢分享
本人学习的代码仓库:springcloudstudy
版本:
Spring Cloud Finchley; Spring Boot 2.0.3
1.服务的注册与发现:Eureka以及高可用Eureka
单机的eureka service创建没有什么难的,利用maven引入spring-cloud-starter-netflix-eureka-server依赖,做好相关的配置,启动项目即可。
客户端注册引入spring-cloud-starter-netflix-eureka-client依赖,做好eureka的service地址配置。
这里注意两个配置:
eureka.client.register-with-eureka: 由于该应用为注册中心,所以设置 为 false, 代表不向注册中心注册自己。
eureka.client.fetchRegistry: 由于注册中心的职责就是维护服务实例,它并不需要去检索服务, 所以也设置为 false。
高可用的情况下,设为默认true。
高可用的eureka在配置方面相对复杂一点,尤其是对于eureka.instance.hostname,prefer-ip-address的理解,这里推荐链接构建高可用Eureka注册中心
内容如下:
1)许多高可用的Eureka配置里都要设置hosts文件,它是必须的吗?
不是必须的,配置hosts文件的目的是使各个Eureka的eureka.instance.hostname不同。
Eureka互相注册要求各个Eureka实例的eureka.instance.hostname不同,如果相同,则会被Eureka标记为unavailable-replicas。我们最终把eureka.instance.hostname取了${spring.cloud.client.ipAddress}的值,这个值取的是当前启动Eureka的机器的IP,这样虽然配置一样但却自动区分了每台机器的Eureka,这时我们再取prefer-ip-address: true,就可以确保机器优先使用IP而不是到hosts解析域名。
2)prefer-ip-address是做什么用的?
直观来说,如果点击下面注册中心的可用实例列表中的地址,访问结果会分以下几个情况:
hostname和prefer-ip-address都没有配置,则访问 主机名:服务名:端口号,如:http://desktop-1fkok7b:8761/info
配置了hostname而没有配置prefer-ip-address,则访问 hostname:服务名:端口号,如:http://myhostname:8761/info
一旦配置了prefer-ip-address,则访问 ipAddress:服务名:端口号,如:http://172.20.10.3:8761/info
在最终方案里我们已经把hostname设置为当前机器IP(${spring.cloud.client.ipAddress}),可以想见prefer-ip-address并不是必须的,但是合理使用它可以避免因为访问主机名而请求不到服务的情况,当然或许还节约了地址解析的损耗(虽然比较小)
3)为什么把hostname设置为当前机器IP?
(这一段的前提是微服务规模在几十个以内)当然也可以设置为域名,但是你要配置hosts(如果配置到所有Docker镜像中显然庞大不够灵活),或者搭建内网DNS服务器(为高可用增加了一层负担),而随着统一配置中心的到来,或许直接使用IP倒是一个相当不错的选择。另外,如果你配置了hostname,那么其它服务注册到你的时候,其它服务的defaultZone要填写defaultZone: http://yourhostname:8761/eureka/ 以确保没有问题,但如果你的hostname配置的就是IP,那其它服务的defaultZone里直接填写IP就可以,如defaultZone:http://172.20.10.3:8761/eureka/ 。
4)上面说的都是在不同机器上启动Eureka,能在同一台机器上启动多个Eureka吗?
当然可以,但是一定要保证各个Eureka的hostname不同,一种办法是常用的配置hosts文件,还有一种,是使用当前机器IP、127.0.0.1和localhost分别作为三个Eureka的hostname,事实证明也是可以的,在文末的Github的项目的no_hosts分支里有相应的实现。但是如果你使用127.0.0.1或localhost,注意一定要设置prefer-ip-address: false 。
5)我在同一台机器上配置hosts,启动三个Eureka实例并设置prefer-ip-address: true,为什么显示unavailable-replicas?
一种原因是,你设置了prefer-ip-address: true,其它服务注册你时应该使用defaultZone:http://yourIP:8761/eureka/,图中使用的仍然是hostname名,导致错误发生。
另一种原因是,三个Eureka都设置了prefer-ip-address: true,导致最后解析出来的hostname都是相同的IP,使副本不可用。这也是4中为什么要设置prefer-ip-address: false的原因。
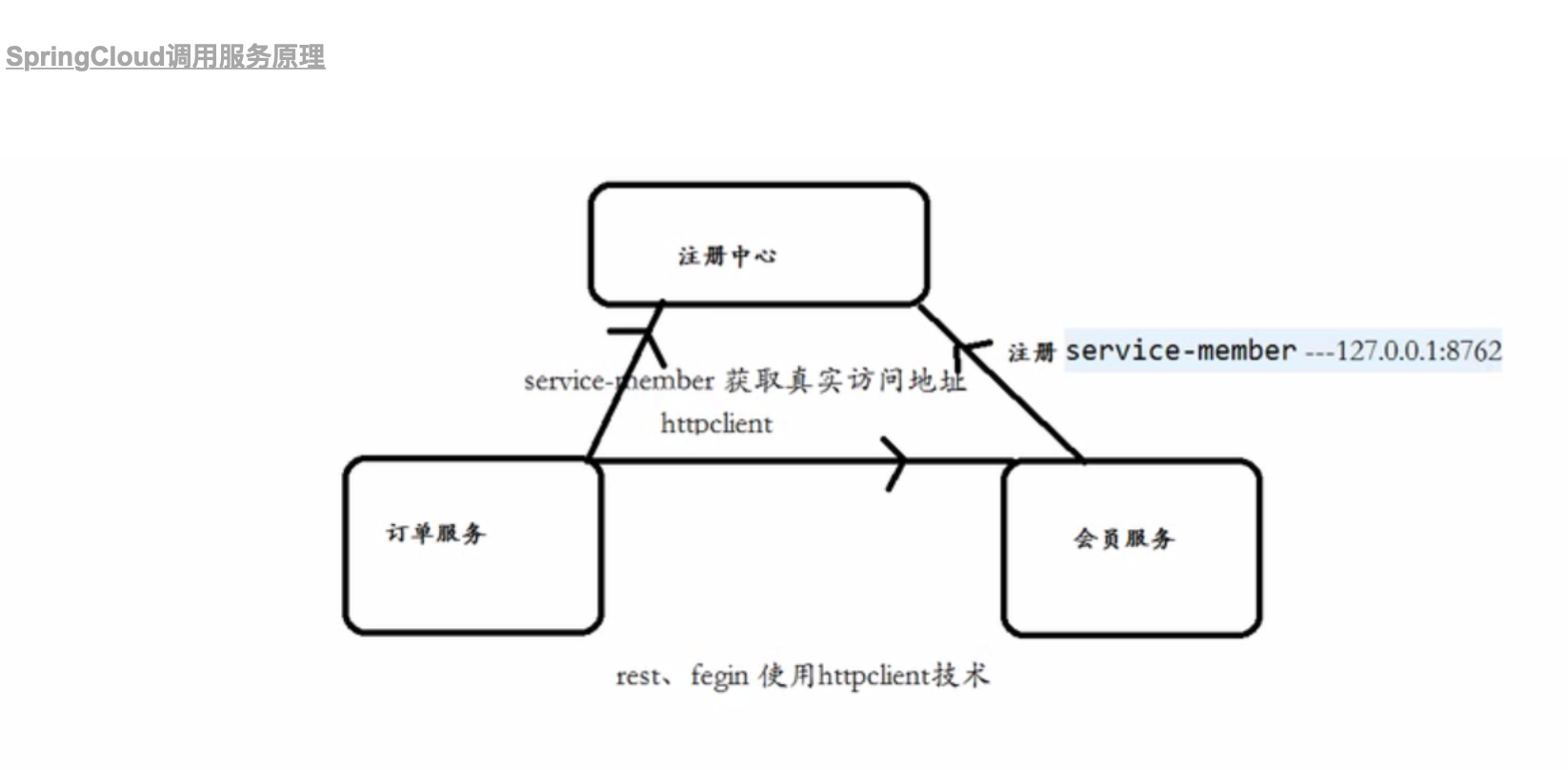
2.服务消费,负载均衡:rest+ribbon或者Feign
springcloud用的是一种客户端负责均衡的模式,即调用方做了负载均衡的配置,ribbon具有负载均衡的能力。
rest+ribbon:引入spring-cloud-starter-netflix-ribbon,通过在restTemplate的Bean上加上@LoadBalanced即可实现负载均衡的效果。
Feign:引入spring-cloud-starter-openfeign依赖,声明式的伪Http客户端,它使得写Http客户端变得更简单,同时具备ribbon负载均衡。
3.断路器:Hystrix,断路器监控:Hystrix Dashboard,断路器聚合监控:Hystrix Turbine
4.路由网关:zuul和Spring Cloud Gateway
5.分布式配置中心:Spring Cloud Config以及其高可用
引入spring-cloud-config-server依赖
其大体的实现理解是这样的,通过springboot为其指定外部配置文件的加载位置来取代jar包之内的配置内容实现,将需要的配置文件存于特定的git上便于管理,config service启动读取该仓库指定分支,指定项目,指定环境的配置信息供其他的微服务加载配置。结合Spring Cloud Bus可以实现动态的更新微服务配置信息,而不需要重启服务。
6.消息总线:Spring Cloud Bus
Spring Cloud Bus 将分布式的节点用轻量的消息代理连接起来。它可以用于广播配置文件的更改或者服务之间的通讯,也可以用于监控。引入:spring-cloud-starter-bus-amqp
目前实践的主要作用是实现通知微服务架构的配置文件的更改,其他什么场景下还可以使用该功能,还缺少认知。
总之其大概作用理解是,通过消息中间件rabbitmq,实现在多服务的情况下,发送一同请求通知,实现所有服务相应的变更。发送通知需要配合spring-boot-starter-actuator依赖。
优化:Spring Cloud Bus可以指定刷新范围,既然/bus/refresh接口提供了针对服务和实例进行配置更新的参数, 那么我们的架构也可以相应做出一些调整。 在之前的架构中, 服务的配置更新需要 通过向具体服务中的某个实例发送请求, 再触发对整个服务集群的配置更新。 虽然能实现功能, 但是这样的结果是, 我们指定的应用实例会不同千集群中的其他应用实例, 这样会 增加集群内部的复杂度, 不利于将来的运维工作。 比如, 需要对服务实例进行迁移,那么我们不得不修改Web Hook中的配置等。 所以要尽可能地让服务集群中的各个节点是对等的。
我们主要做了以下这些改动:
1)在ConfigServer中也引入SpringCloudBus, 将配置服务端也加入到消息总线中来。
2)/bus/refresh请求不再发送到具体服务实例上, 而是发送给Config Server, 并 通过destination参数来指定需要更新配置的服务或实例。
通过上面的改动,我们的服务实例不需要再承担触发配置更新的职责。 同时,对于Git 的触发等配置都只需要针对ConfigServer即可, 从而简化了集群上的一些维护工作。
7.服务链路追踪:Spring Cloud Sleuth
引入spring-cloud-starter-zipkin,server-zipkin通过直接起官方jar包即可,可通过浏览器打开9411默认端口查看zipkin界面。其作用类似于我们在开发过程中打印日记时,要加上请求唯一的traceId,便于后续request的跟踪于查询。
问题:
使用spring-cloud-starter-zipkin + 独立部署的zipkin 进行链路追踪,但是如果项目同时使用 rabbitmq和spring-cloud-starter-bus-amqp 会导致 zipkin收集不到信息
原因:
spring-cloud-starter-bus-amqp 中包含了 spring-rabbit的全部组件。
在引入 spring-cloud-starter-zipkin 后,默认与zipkin通信使用的是 http的方式。
同时引入 spring-rabbit后,与zipkin通信会变成使用rabbitmq。
解决方法:
配置文件中加入或修改以下属性。就可以继续使用http的方式向zipkin通信。spring.zipkin.sender.type: web
Sampler.ALWAYS_SAMPLE
Sampler:采样器,根据traceId来判断是否一条trace需要被采样,即上报到zipkin
Sampler.ALWAYS_SAMPLE 永远需要被采样 Sampler.NEVER_SAMPLE 永远不采样
spring.sleuth.sampler.probability=1.0表示以 100% 的概率将链路的数据上传给 Zipkin Server , 在默认情况下 , 该值为0.1


